
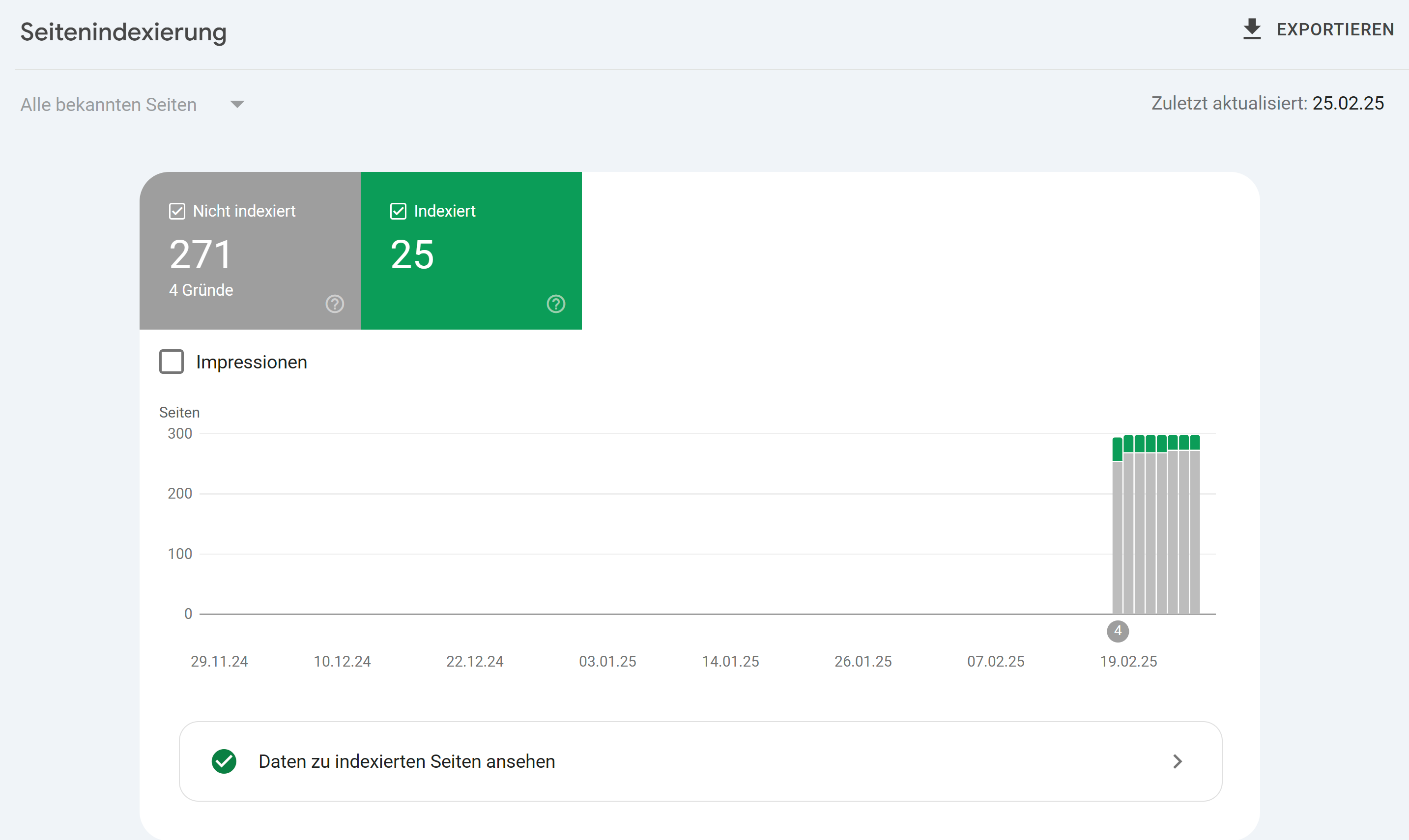
Google hat mein Blog immer noch größtenteils deindexiert und die Seiten, die Google im Index behalten hat, sind komplett zufällig bis erratisch. Der „Fehler“, wenn man ihn so nennen will, lautet „Gecrawlt – zurzeit nicht indexiert“. Die Standardinterpretation dafür ist, dass Google den Inhalt schlicht nicht für relevant für irgendjemanden hält. Das ist bei einem persönlichen Blog dann schon etwas, was man erst mal verdauen muss.
Google hat je nachdem, welchen Counter man benutzt, 80% bis 90% Marktanteil. Aber mein Blog war nie wirklich auf Google angewiesen. Die meisten menschlichen Leser haben auf einen Link auf einem meiner Social-Media-Profile geklickt. Die zweitgrößte Gruppe gibt tatsächlich die Adresse ein oder nutzt ein Privacy-Plugin, das die Referrer entfernt. Dann kommt schon die Gruppe mit den RSS-Readern. Von etwa 1600 Besuchen am Tag, die ich nicht den Bots zuordnen kann, kamen vielleicht 200 von Google und jetzt sind es 8, wobei ich nicht erklären kann, wie diese 8 das geschafft haben, denn die Seiten, die sie ansteuerten, sind wirklich nicht im Index.
Ich habe jetzt für Google ein paar Extra Würste im Code gebraten, aber da alle anderen Suchmaschinen mit eigenem Index die Inhalte meines Blogs weiterhin für relevant halten, habe ich keine weiteren Änderungen vorgenommen. Im Zuge eines Neuaufbaus meiner Webauftritte kommt aber:
- eine englischsprachige Version (eigene Domain)
Seien wir ehrlich; Deutsch ist die Sprache der Bösewichte in allen besseren Bond-Filmen, aber sonst eher Nische. In meinem Beruf hat man viel mit Englisch zu tun und die Deepl-Version meines Blogs hat eben die KI-Probleme. Da kann ich auch gleich am Samstag loslegen und auf Englisch schreiben. - strengere Selektion bei alten Artikeln
Da ist wirklich viel, dass nicht mehr erhalten werden muss bzw. gelöscht werden sollte. - ein richtiges Archiv,
das die Artikel aufnimmt, die die Relevanzkriterien nicht erfüllen, aber erhalten bleiben sollten. - automatischer Ablauf von neuen Artikeln
Das CMS bietet die Funktion und jetzt werde ich sie nutzen. Bei der geplanten Frequenz von 3 Artikeln pro Monat bleiben mit 2 Jahren Haltbarkeit also 36 Artikel im Blog plus die, bei denen ich den Ablauf verhindert habe.
Update 28.2.:
Da Fragen kamen: Ja ich speichere die Server-Logs. Allerdings läuft im Logrotate-Skript vor dem Zippen ein mal SED über die IP-Addressen und tauscht das letzte Oktett gegen einen gesalzenen Hash der auch von 2 bis 255 geht und auch die Host-ID / PTR werden mit einer Positivliste abgeglichen und ggf. Pseudonymisiert. Dadurch kann ich alle Auswertungstools wie GoAccess, Webalizer, ELK weiter nutzen, aber habe keine persönlichen Daten in den Logs.
Wenn Dir der Artikel gefallen hat, versuch Doch mal:
Kommentare
Keine Kommentare
Kommentare