
Wie schon in Teil 1 erwähnt, hat sich in den letzten Jahren viel an Art wie „die Leute“ mit Daten umgehen verändert. In erster Linie heißt die Änderung „Cloud“, aber auch „Wegfall klassischer Computer“.
Wenn man nur seine Dokumente nur gegen Gerätedefekt schützen will, kann man sie in einer Cloud wie icloud, GoogleDrive oder oneDrive ablegen und man ist fertig. Das Vertrauensproblem und die möglichen Auflösungen inklusive inversen Gefangenendilemma behandele ich in der anderen Artikelreihe.
Bei der Planung des Backups hat sich folgende Reihenfolge bewährt:
+ Abzudeckende Risiken festlegen
+ Quelldaten erfassen
+ Backupfrequenz und Volumenbedarf festlegen
+ Zielmedien bestimmen
+ Aufgaben festlegen
+ Review-Termin eintragen
Ursachen für Datenverlust
Verluste 44
Benutzerfehler 32
Softwarefehler 14
Wurm- und Virenbefall 7
Naturkatastrophen 3
Diese Verteilung ist aus Reviews on Security Issues and Challenges in Cloud Computing.
Im Privaten erlebe ich zu oft, dass viele Backup-Lücken einfach dadurch entstehen, dass man sich einfach keine Gedanken über die Menge und den Wert der jeweiligen Daten gemacht hat. Rechner und Smartphones sind mittlerweile Toaster. Sie sind einfach da wie Toaster, Bleistifte oder Türklinken. Von Gamern und Enthusiasten abgesehen, nimmt niemand sie noch bewusst wahr und man benutzt sie als Selbstverständlichkeit.
Auf Twitter liest man regelmäßig von Notebooks oder Smartphones die in Zügen mitsamt Bachelor- oder Masterarbeiten oder unwiederbringlichen Fotos vergessen werden. Verluste durch Einbrüche sind selten, weil Rechner entweder schnell nicht viel wert sind oder im Fall von z.B. Apple nicht mal mehr als Teilespender taugen, da durchserialisiert.
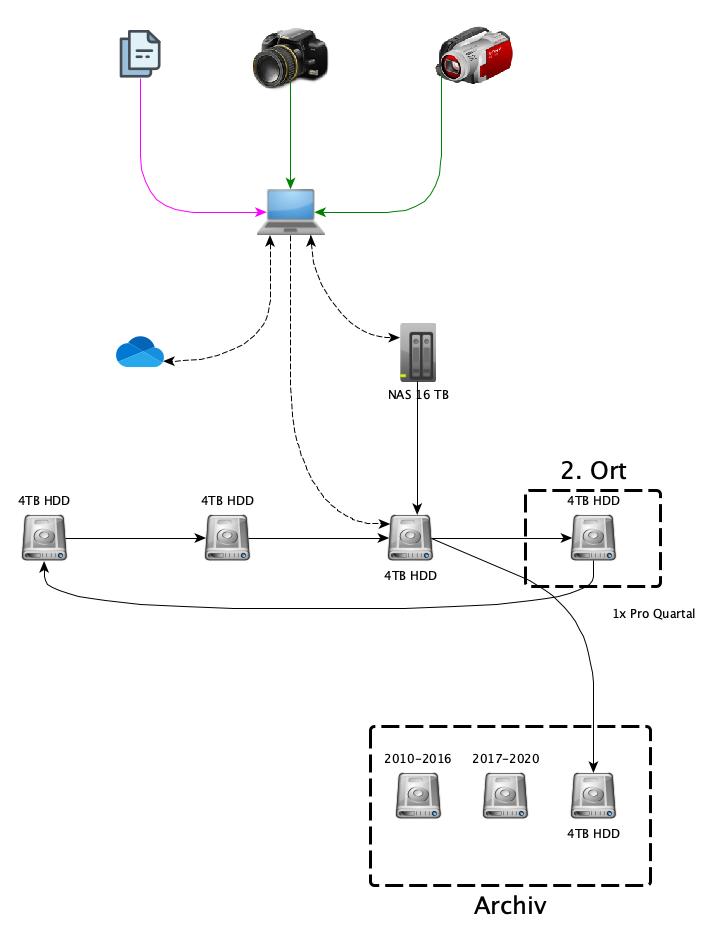
Gegen Defekte, Benutzer- und Softwarefehler reicht bereits eine zweite Kopie z.B. in einem NAS oder in einer Cloud.
Gegen Wurm- und Virenbefall muss diese dann offline sein z.B. auf separaten Festplatten (in meinem Fall 4B SATA-Festplatten).
Gegen Naturkatastrophen hilft nur Lagern an einem zweiten Ort weiter weg in einem wasserdichten und feuerfesten Behältnis. 2018 hätte aber niemand glauben wollen, dass man auch für eine weltweite Pandemie planen muss, die dazu führt, dass man aufgrund von Ausgangssperren ganze Landesteile nicht mehr erreichen kann oder will.
Der häufigste Fall einer „Naturkatastrophe“ ist aber immer nich Überspannung durch Gewitter oder Elektrostatische Entladung durch Benutzerfehler (Kunstfasersocken und Schurwolleteppich…). Zwar sind Rechner diesbezüglich erheblich besser geworden und Notebooks durch die externen Netzteile und Nutzung von WLAN im Allgemeinen gut geschützt, aber bei weitem nicht unverwundbar.
Ich habe auf allen Rechnern zwei Orte für meine Daten:
Das „eigene Dateien“ oder dessen Äquivalent und einen Ordner „Repository“. Ich achte streng darauf, alle meine manuell angelegten Daten nur in diese beiden Ordner zu speichern und die anderen Daten im Zweifel nicht zu brauchen.
- Ich sichere meine aktiven Daten unter „eigene Dateien“ auf meinem Rechner und parallel in der Cloud.
- Rohdaten laufen zwar im Rechner im Repository auf, aber würden jede bezahlbare Cloud sprengen. Daher werden Sie ins NAS gespiegelt, wenn dieses erreichbar ist.
In meinem Fall profitiere ich von einem geschlossenen Datenmodell. Ich muss nur 9 unterschiedliche Datentypen aus 7 Quellen sichern. Wie man vorgeht, wenn man eine komplexere Verteilung hat, zeige ich für Windows und Linux im kommenden Teil.
Beispielrechnung mit meinen Daten
| Quelle | Art der Daten | Cloud | Backup | Frequenz | Volumen monatlich | Langzeit-Sicherung | frequenz | Volumen pro Jahr |
|---|---|---|---|---|---|---|---|---|
| Telefon | Fotos & Videos | ja | NAS | wöchentlich | 12GB | Festplatten | Quartalsweise | 144GB |
| Tablet | Zeichnungen | ja | NAS | wöchentlich | 0,1GB | Festplatten | Quartalsweise | 1,2GB |
| Smart-TV | Links und Browserhistory | nein | NAS | permanent | 0,1GB | Festplatten | Quartalsweise | 1,2GB |
| Videokamera | Film-Rohdaten | nein | NAS | täglich | 200GB | Archiv | Quartalsweise | 2400GB |
| Fotoapparat | Foto-Rohdaten | nein | NAS | täglich | 2GB bis 10GB | Festplatten | Quartalsweise | 60GB |
| Audio-Recorder | Audio-Rohdaten | nein | NAS | täglich | 2GB bis 10GB | Festplatten | Quartalsweise | 60GB |
| Rechner | Dokumente, bearbeitete Medien | ja | Cloud | täglich | 10GB bis 50GB | VXA2-Tapes und RDX-Module | Quartalsweise | 300GB |
| Rechner | digitalisierte Dokumente | ja | NAS | täglich | 1GB bis 10GB | Festplatten | Quartalsweise | 20GB |
| Rechner | digitalisierte CDs | ja | NAS | täglich | 1GB bis 10GB | Festplatten | Quartalsweise | 10GB |
Macht etwa 3TB pro Jahr
Ein Backup-System für mich muss also mit 250GB neuen Daten im Monat klarkommen.
Bei der Wahl der Backup-Frequenz sind die Benutzerfehler der PITA. Wenn man acht Stunden in ein neues Dokument investiert und der Rechner es beim BSOD-Seppuku mit in die Geisterwelt nimmt, ist das im gewerblichen Umfeld schnell ein vierstelliger Schaden, aber ein nächtlich durchgeführtes Backup würde es nicht abdecken. Gegen solche Benutzerfehler hilft in erster Linie die Anwendungs-Konfiguration mit einer automatischen Sicherung zu erzwingen in Kombination mit einem Cloudsync oder echtem Arbeiten auf dem Netzlaufwerk, was man früher aus diversen Gründen vermied.
Bei den Zielmedien hatte ich bislang 3,5“ SATA-Platten im Einsatz. Notebookplatten in Gehäusen und Etuis sind sehr robust und dazu noch preiswert, aber langsamer, als ihre schneller drehenden 3,5“ Entsprechungen. Wer jetzt genau aufgepasst hat, merkt, dass ich für Rohdaten die dritte Kopie aus der 3-2-1-Regel erst nach 7+1 Tagen erreiche. Das Risiko geht aber m.E. in Ordnung.
Ich stecke jeden Samstag eine neue Platte ans NAS und eine Service-VM kümmert darin sich um das Backup und dessen Verschlüsselung. Als Review speichere ich die Logs mitsamt der Prüfsummenvergleiche der gesicherten Daten mit den Originalen in einem Archiv-Ordner. Die Cloud hingegen wird von einem Service Rechner in einer anderen Colocation zunächst auf Festplatten und final auf VXA2-Tapes gesichert.